원문: http://www.cs.wustl.edu/~schmidt/PDF/proactor.pdf
인터넷에 번역된 문서를 찾을수는 있었지만… 번역이 매끄럽지는 않다. 그래서 직접 번역.
서문
현대의 운영체계들은 동시에 실행되는(*concurrent) 어플리케이션들을 개발하기 위한 여러가지 메카니즘을 제공하고 있다.
*동기식 멀티쓰레딩 은 동시에 여러 작업을 수행하는 어플리케이션을 개발하는데 있어 인기있는 메카니즘 이다. 그런데 가끔, 스레드들은 성능상의 오버헤드가 크고(즉 자원을 더 많이 필요로 한다), 동기화 처리에 대한 원칙들과 패턴들에 대해서도 깊은 이해를 요구한다.
이런 사유로, 점차 많은 수의 운영체계에서는 멀티 쓰레딩의 많은 오버헤드와 복잡성을 완화 시키면서 동시성의 이점을 제공하는 비 동기적 메카니즘을 지원하고 있다.
이 문서에서 소개된 Proactor 패턴은 OS가 제공하는 비동기적 메카니즘을 효율적으로 이용하기 위해서는, 어플리케이션들과 시스템을 어떻게 구성해야 하는지에 대해 기술하고 있다.
어플리케이션이 비동기적 동작을 호출할때, OS 는 어플리케이션을 대신해서 작업을 수행한다.
이 덕분에 어플리케이션에서는 작업들 갯수만큼 쓰레드를 생성하지 않고도, 동시에 여러 작업을 수행할 수 있다.
따라서 Proactor 패턴은 동시 실행 프로그래밍을 단순화 시키고, 좀더 작은 수의 쓰레드를 사용할수 있으므로 성능의 향상을 가져오며, OS제공의 비동기 동작을 최대한 활용할수 있게 해준다.
(역자 주) Synchronous multi-threading : 흔히 “동기식” 멀티 쓰레딩 이라고 번역된다. 동기식 이라고 하는 이유는, 요청이 올때마다 즉시 완료될때까지 수행되기 때문이다. 이것은 blocking 동작이라는 의미도 내포하고 있다. 개인적으로는 이 동기식 멀티 쓰레딩이란 말은 쉽게 의미가 와닿지 않는다라고 생각하지만, 일반적으로 널리 사용 되므로, 이 문서에서도 그대로 사용 하기로 한다 (;-)
(역자 주) concurrent :동시실행, 병행처리등으로 나타내질수 있겠지만, concurrent 와 Parallel 의 차이점을 좀더 확실하게 구분하고 싶다면 다음글을 참고. http://www.linux-mag.com/id/7411/
1. 의도
비동기적인 이벤트들의 완료시점에 호출되는 이벤트 핸들러들을 위한 디스패칭과 *demultiplexing을 지원한다.
이 패턴은 완료 이벤트들의 디멀티플렉싱과 그것에 해당되는 이벤트 핸들러들의 *디스패칭을 통합시킴으로서 비동기적 어플리케이션 개발을 단순화 시킨다.
- 디멀티플렉싱이란 예를들어, 어떤 서버가 있다고 하면, 클라이언트가 보낸 메시지를 해석해서 그에 알맞은 작업을 시작하는 것을 말한다.
- 디스패칭이란 간단히 말해 이벤트 핸들러를 호출한다는 것이다.
2. 동기
이 장에서는 Proactor 패턴을 사용하기 위한 배경과 동기를 제공한다.
2.1 특정상황 및 목적
Proactor 패턴은 어플리케이션이 동시적 작업수행에 있어서 동기적 멀티 쓰레드나 reactive 프로그래밍 사용등의 제약 없이 성능상의 이점을 요구할때 적용 되어져야 한다.
이런 이점들을 보여주기 위해서, 동시에 여러 작업을 수행해야 하는 네트워크 어플리케이션을 고려해보자.
예를 들어, 고성능 웹서버는 여러 클라이언트로부터의 HTTP 요청들을 동시에 처리할수 있어야 한다.
그림1 은 웹브라우져와 웹서버와의 전형적인 상호 작용을 보여주고 있다.
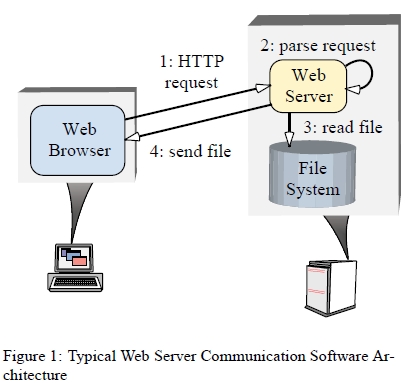
사용자가 브라우져에게 URL을 열것을 지시하면, 브라우져는 HTTP GET 요청을 웹서버로 전송한다.
서버는 요청을 받으면 즉시 분석 및 유효성을 체크해서 브라우저에게 특정 파일을 전송한다.
고성능 웹서버는 다음 목적들에 대한 해결책이 필요하다.
-
동시 처리 - 서버는 동시에 여러 클라이언트의 요청을 처리해야한다.
-
효율적인 처리 - 지연(latency)을 최소화 하고, 처리량을 극대화 하며, 불필요한 CPU(들) 사용을 피해야 한다.
-
간단한 프로그래밍 - 효율적인 동시 처리 방법들을 간단하게 사용할수 있게끔 서버 디자인이 가능해야 한다.
-
적응성(Adaptability) - 새로 만들어지거나 개선된 전송 프로토콜들(예를 들면 HTTP1.1)을 통합하는데 있어서 최소한의 관리 비용이 투입되어야 한다.
웹서버를 구현할때 사용할수 있는 몇가지 동시 처리 방법을 나열해 보면, 여러개의 동기식 쓰레드 사용, reactive 동기 이벤트 디스패칭 사용, 그리고 proactive 비동기적 이벤트 디스패칭 을 이용하는 것이다.
아래에서 우리는 전통적인 접근 방법의 단점을 검토해보고, Proactor 패턴이 어떻게 고성능 동시 처리 어플리케이션에 대해 효율적이고 유연한 비동기적 이벤트 디스패칭 방법을 위한 강력한 테크닉을 제공하는지 설명 할 것이다.
2.2 전통적인 동시 처리 모델들의 일반적인 덫과 함정들
동기식 멀티 쓰레딩과 reactive 프로그래밍은 동시처리를 구현하는데 있어서 일반적인 방법들이다. 이 장에서는 이들 모델의 결점들에 대해 기술한다.
2.2.1 다수의 쓰레드들을 이용한 동시 처리
아마도 동시처리 웹서버를 구현하는데 있어서 가장 직관적인 방법은 동기식 멀티 쓰레드 사용 일 것이다.
이모델에서는 여러개의 서버 쓰레드들이 여러 클라이언트들 로부터의 HTTP GET요청들을 처리한다. 각 쓰레드들은 연결 수립, HTTP 요청 읽기, 요청 분석, 그리고 파일 전송 작업을 동시적으로 수행한다.
결과적으로 각 동작들은 완료될때까지 블럭된다. 동기식 쓰레딩의 주된 장점은 어플리케이션 코드의 간결성이다.
특히, 웹서버가 클라이언트A 에 대해서 수행하는 작업들은 대부분 클라이언트B 에 대한 작업들에 대해서 독립적이다.
그러므로 쓰레드간에 공유되는 정도가 낮고 , 동기화 필요성도 최소화되므로, 별도의 쓰레드들에서는 서로다른 요청들에 대한 처리를 쉽게 할수 있다.
게다가 별도의 스레드 안에서는, 개발자들이 직관적인 순차적 명령들과 블럭킹 동작들을 이용해서 어플리케이션 로직을 수행 할수 있다.
그림 2는 쓰레드를 이용해서 웹서버가 어떻게 여러 클라이언트를 동시에 처리하는지 보여준다.
이 그림에서 동기식 연결 수락 객체(Sync Acceptor object) 를 볼수있는데, 네트워크 연결 수락을 동기식으로 수행하는 서버쪽 메커니즘을 추상화 하고 있다.
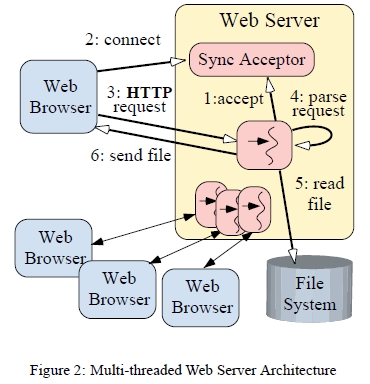
하나의 연결마다 하나의 쓰레드를 생성해서 HTTP GET 요청을 처리하는 동시 처리 모델에서 각 단계는 아래와 같이 요약된다.
-
각 스레드는 accept 호출에서 클라이언트의 연결을 기다리면서 블럭된다.
-
클라이언트가 서버 연결을 시도하고, 연결이 수락된다.
-
새로운 클라이언트의 HTTP요청이 동기적으로 들어온다.
-
요청이 분석된다.
-
서버는 요청된 파일을 동기적으로 읽는다;
-
파일이 동기적으로 클라이언트에게 전송된다.
이 동기적 쓰레딩 모델의 C++ 코드 예제가 Appendix A.1에 있다.
위에서 기술한것처럼, 동시에 연결된 각 클라이언트는 전담 서버 쓰레드에 의해서 서비스를 제공 받게 된다.
이 스레드는 요청된 작업을 동기적으로 완료한 후, 다른 HTTP 요청들에 대한 서비스를 제공한다. 그러므로 웹서버는 다수의 클라이언트에 대해서 서비스를 제공하는 동안 동기식 입/출력 을 수행하기 위해서 다수의 스레드를 생성해야만 한다.
이런 동기식 멀티 쓰레딩 모델이 비록 직관적이고, 멀티 CPU 플랫폼에 비교적 효율적으로 적용된다고 해도, 다음과 같은 약점들이 존재한다.
-
쓰레드 정책이 동시처리 정책과 강한 결합도를 갖는다 : 이 구조에서는 각 연결 클라이언트에 대한 전담 쓰레드가 필요하다. 동시 처리 어플리케이션은 동시에 서비스 되어야 하는 클라이언트의 수 보다는, 사용 가능한 자원들 (예를 들면 thread pool을 사용하는 조건이라면 CPU 갯수) 에 의해서 스레드 정책을 조정함으로서 좀 더 최적화 될 수 있다.
-
동기화 처리 복잡도 증가 : 쓰레드 사용은 서버의 공유 자원들(캐쉬된 파일들이나 웹페이지 히트 수 로그 정보 등 )을 연속적으로 접근하기 위해 필요한 동기화 처리의 복잡도를 증가시킨다.
-
성능 오버 헤드 증가 : 쓰레드로 처리시 문맥전환, 동기화, CPU간 데이터 이동[4] 등으로 인해서 형편없이 동작 할 수도 있다.
-
이식성이 없음 : 쓰레드 처리는 모든 운영체계 플랫폼에서 가능하지 않을수도 있다. 더군다나, OS 플랫폼끼리는 선점형 , 비 선점형 스레드를 지원함에 있어서 큰 차이점이 있다. 따라서, OS플랫폼들간 동일하게 동작하는 멀티 쓰레드 서버를 만드는것은 매우 어려운 일이다.
이런 약점들의 결과로서, 동시 처리 웹서버를 개발하는데 있어서, 멀티 스레드 처리는 종종 가장 효율적이지도 않고 복잡도가 낮은 방안도 아니게 된다.
2.2.2 Reactive 동기적 이벤트 디스패칭에 의한 동시처리
동기적인 웹서버를 구현하는 또다른 일반적인 방법은 반응적(reactive) 이벤트 디스패칭 모델을 이용하는것이다.
Reactor패턴은 어플리케이션이 이벤트 핸들러들을 시작 디스패처(Initiation Dispatcher)에 어떻게 등록할수 있는지 설명한다.
Initiation Dispatcher는 블록킹 없이 작업을 시작할수 있을때 이벤트 핸들러에게 통지한다.
단일 쓰레드 동시처리 웹서버인 경우, 반응적(reactive) 이벤트 디스패칭 모델을 사용할수 있는데, 이때는 이벤트 루프내에서 Reactor가 적절한 작업들을 시작한다는 통지를 보내길 기다린다.
웹서버에서 reactive 작업의 예는 Initiation Dispatcher에 Acceptor 를 등록하는 것이다.
네트워크 연결로부터 데이터가 도착하면, dispatcher는 Acceptor를 콜백한다. Acceptor는 네트워크 연결을 수락하고 HTTP 핸들러를 생성한다.
이 HTTP 핸들러는 Reactor에게 등록이 되고, 그 연결로부터 들어오는 URL 요청을 웹서버의 단일 쓰레드 제어 하에서 처리한다.
그림 3,4 는 반응적(reactive) 이벤트 디스패칭을 사용하는 웹서버가 어떻게 다수의 클라이언트를 처리하는지 보여준다.
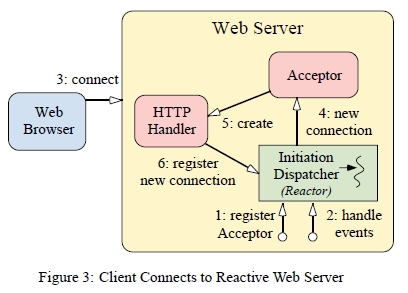
그림3은 클라이언트가 웹서버로 연결할때 이루어지는 절차들을 보여주고 있다. 그림4는 웹서버가 클라이언트의 요청을 어떻게 처리하는지를 보여준다.
그림3의 절차들에 대한 순서는 다음과 같이 요약 될 수 있다.
-
웹서버는 새로운 연결을 수락하기 위해 Acceptor를 Initiation Dispatcher 에 등록한다.
-
웹서버가 Initiation Dispatcher의 이벤트 루프를 호출한다.
-
클라이언트가 웹서버에 연결한다.
-
Acceptor는 Initiation Dispatcher에 의해 새로운 연결 요청 통지를 받고, 연결을 수락한다.
-
Acceptor가 새 클라이언트에 서비스 하기위해 HTTP Handler 를 생성한다.
-
HTTP Handler는 클라이언트의 요청데이터를 읽기위해 Initiation Dispatcher 에 연결을 등록한다 (클라이언트의 요청데이터는 연결이 읽기 가능 상태로 되었을 때 받을수 있다).
-
HTTP Handler 는 새로운 클라이언트로 부터의 요청에 대한 서비스를 제공한다.
그림 4 는 반응적(reactive) 웹서버가 HTTP GET요청에 대해 서비스 할때, 각 절차들의 순서를 보여준다.
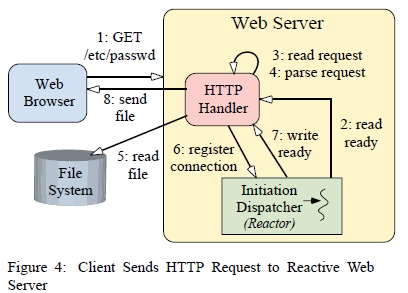
이 과정은 다음처럼 기술된다.
-
클라이언트가 HTTP GET 요청을 보낸다.
-
클라이언트 요청 데이터가 도착하면 Initiation Dispatcher가 HTTP Handler에게 알린다.
-
요청이 non-blocking 방식으로 읽혀지는데, 읽기 작업으로 인해서 호출 쓰레드가 블럭된다면 EWOULDBLOCK 을 리턴하게 된다 (2,3단계가 요청이 완전하게 읽혀질때까지 반복된다).
-
HTTP Handler가 HTTP요청을 분석한다.
-
요청된 파일이 동기식으로 파일시스템으로부터 읽혀진다.
-
HTTP Handler가 데이터 전송을 위한 연결을 Initiation Dispatcher에 등록한다.
(연결이 쓰기 가능 상태로 되었을 때 클라이언트로 전송된다). -
Initiation Dispatcher 가 TCP connection연결이 쓰기 가능 상태로 되었을때 HTTP Handler에게 알린다.
-
HTTP Handler가 요청 파일을 non-blocking 방식으로 전송하는데, 쓰기 작업으로 인해서 호출 쓰레드가 블럭된다면 EWOULDBLOCK 을 리턴하게 된다 (7,8 단계가 데이터가 완전하게 전달 될때까지 반복된다).
이 모델을 웹서버에 적용한 C++ 코드 예제가 부록 A.2 에 있다.
Initiation Dispatcher는 단일 쓰레드에서 동작하기 때문에, 네트워크 입/출력 작업들은 Reactor의 제어 하에서 non-blocking 방식으로 동작한다.
만약 현재 작업에서 더이상 진전이 안되는 상황이면, 그 작업은 시스템 동작 상태를 모니터하고 있는 Initiation Dispatcher로 넘겨진다.
그리고 작업이 다시 진전될수 있을때, 적절한 핸들러가 통지를 받게 된다. 이러한 reactive모델의 주된 장점은 이식성, 단순한 동시처리 제어(단일 쓰레드 처리는 동기화나 문맥전환이 불필요하므로)로 인한 낮은 오버헤드 그리고 디스패칭 메커니즘과 어플리케이션 로직을 분리함으로서 모듈화가 가능하다는 점이다.
그럼에도 불구하고 이 접근 방법은 다음과 같은 약점들을 가지고 있다.
-
복잡한 프로그래밍 : 위 목록에서 보여진 것처럼 프로그래머들은 특정 클라이언트에게 서비스할때 서버가 블럭되지 않도록 하기 위한 복잡한 로직을 작성해야 한다.
-
멀티 쓰레드 처리에 대한 운영체계 지원 부족 : 대부분의 OS들은 select 시스템 호출[7] 로서 reactive 디스패칭 모델을 구현하고 있다. 그런데, select는 이벤트 루프 내에서 동일한 descriptor set에 대한 대기 쓰레드를 하나만 허용 한다. 이것이 reactive 모델을 고성능 어플리케이션에 적합하지 않는 이유인데, 왜냐하면 하드웨어 병렬처리를 효율적으로 이용할수 없기 때문이다.
-
태스크 스케쥴링 : 선점형 쓰레드를 지원하는 동기식 멀티 쓰레드 구조에서는 가용한 CPU에 대해 실행가능한 쓰레드들을 스케쥴하고 시분할 처리를 하는것은 운영체계의 몫이다. reactive 구조에서는 어플리케이션에 오직 하나의 쓰레드만이 존재하기 때문에 이러한 스케쥴링 지원을 받을수 없다. 그래서 개발자들은 웹서버에 연결된 모든 클라이언트들을 서비스 하려면 쓰레드 처리를 신중하게 시 분할해야 한다( 역자주: 즉 특정 클라이언트에게 과도하게 서비스 시간을 제공하면서 전체 클라이언트 처리가 지연되는 상황을 만들면 안된다). 이것은 non-blocking 작업들을 짧은 시간동안만 수행함으로서 성취 될 수 있다.
이러한 약점들 때문에, reactive event dispatching 은 하드웨어 병렬처리가 가능한 경우에는 가장 효율적인 모델이 아니다. 이 모델은 또한 blocking 입/출력을 피하기 위한 필요성 때문에, 상대적으로 높은 수준의 프로그래밍 복잡도를 갖게 된다.
2.3 해결방안: Proactive 동작들에 의한 동시처리
OS 운영체계가 비동기 동작들을 지원하는 경우, 고성은 웹서버를 구현하는 효율적이고 편리한 방법은 proactive event dispatching을 사용하는 것이다.
이 방법을 사용해서 설계된 웹서버는 한개 혹은 그 이상의 제어 쓰레드들로 비동기 동작의 완료를 처리한다. 그러므로 Proactor 패턴은 완료 이벤트 디멀티플렉싱과 이벤트 핸들러 디스패칭을 통합함으로서 비동기 웹서버를 단순화 시킨다.
비동기 웹서버는 Proactor 패턴을 활용하기 위해, 먼저 OS 에 대해서 비동기 동작을 발생 시키고 (역자주: 즉, 비동기로 처리하기를 원하는 작업을 먼저 시작시키고) 해당 작업이 완료시에 웹서버로 통지해줄 Completion Dispatcher 에 콜백을 등록하게 된다.
그럼 운영체계는 웹서버 대신 작업을 수행한 이후에, 그 결과를 잘 알려진 위치에 있는 큐에 저장한다.
완료 디스패쳐(Completion Dispatcher)는 완료 통지들을 이 큐에서 뽑아서 적절한 콜백(어플리케이션에 특화된 코드, 즉 여기서는 웹서버 로직)을 실행하는 역활을 수행한다.
그림 5와 6은 이 모델을 사용한 웹서버가 하나혹은 그이상 쓰레드 내에서 어떻게 다수의 클라이언트를 동시에 다루는지를 보여준다.
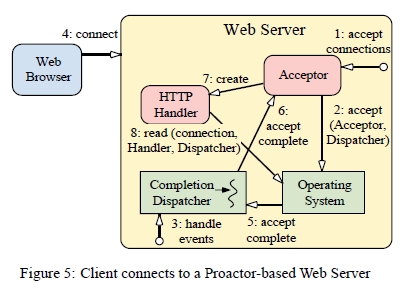
그림5는 클라이언트가 웹서버로 접속할때의 절차들의 순서를 보여주고 있다.
-
웹서버는 Acceptor 에게 비동기 accept 시작을 지시한다.
-
Acceptor가 OS에 의한 비동기 accept를 *시작시키면서, 완료 디스패처(Completion Dispatcher)에게 Acceptor 자신을 완료 핸들러(Completion Handler) 및 참조(reference) 역활로 전달한다. 완료 디스패처는 비동기 accept 호출이 완료 되었을때 Acceptor에게 통지하기 위해서 사용된다.
-
웹서버가 완료 디스패처의 이벤트 루프를 동작시킨다.
-
클라이언트가 웹서버로 접속한다.
-
비동기 accept작업이 완료 되었을때, OS 가 완료 디스패처에게 통지한다.
-
완료 디스패처가 Acceptor에게 알린다.
-
Acceptor는 HTTP Handler를 생성한다.
-
HTTP Handler는 클라이언트로부터의 요청 데이터를 위한 비동기 read작업을 *시작시키면서, 자신을 완료 핸들러로와 참조점으로서 완료 디스패처로 전달한다. 완료 디스패처는 비동기 read 호출이 완료 되었을때 HTTP Handler에게 통지하기 위해서 사용된다.
(역자 주) 비동기 작업은 운영체계가 대신 해주는 것이기 때문에 “시킨다” 고 번역하였다.
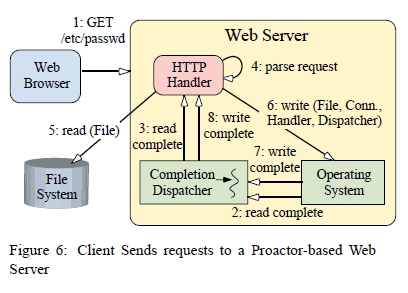
그림 6은 proactive 웹서버가 HTTP GET 요청을 서비스 하기 위한 절차들의 순서를 나타낸다.
이 절차들은 다음과 같다 :
-
클라이언트가 HTTP GET요청을 보낸다.
-
읽기 작업이 완료되서 OS 가 완료 디스패처에게 통지한다.
-
완료 디스패처는 HTTP 핸들러에게 알린다 (2,3단계가 전체 요청이 수신될 때까지 반복됨).
-
HTTP 핸들러가 요청을 분석한다.
-
HTTP 핸들러가 요청파일을 동기식으로 읽는다.
-
HTTP 핸들러가 클라이언트 연결에 파일을 쓰기(전송) 위한 비동가 작업을 시작하면서, 자신을 완료 핸들러 및 참조 역활로 완료 디스패처에 전달한다. 완료 디스패처는 비동기 write가 완료 되었을때 HTTP Handler에게 통지하기 위해서 사용된다.
-
쓰기 작업이 완료 됬을때, OS는 완료 핸들러에게 통지한다.
-
그럼, 완료 디스패처는 완료 핸들러에게 알려준다 ( 파일이 완전히 전달될 때까지 6-8 단계가 계속된다).
이 모델이 적용된 웹서버의 C++ 예제 코드가 8 장에 나온다. Proactor 패턴을 사용하는것의 주요 이점은, 어플리케이션이 여러개의 쓰레드를 가질 필요없이 여러 동시처리 작업들이 시작되고 병렬로 동작 할수 있다는 점이다. 어플리케이션에 의해서 작업들이 비동기로 시작되고, 운영체계의 입/출력 서브 시스템 내에서 완료될때까지 동작하게 된다. 그러면, 작업을 시작한 쓰레드는 이제 또 다른 요청에 대한 서비스를 제공할수 있다.
위 예제에서 예를 들면, 완료 디스패처는 다음처럼 단일 쓰레드로 동작될 수도 있었다.
HTTP 요청들이 도착하면, 단일 완료 디스패처 쓰레드는 요청을 분석하고, 파일을 읽고, 클라이언트에게 응답을 보낸다. 응답이 비동기적으로 보내지기 때문에, 여러 응답들을 동시에 전송 할수도 있었을 것이다. 더군다나, 동기식 파일 읽기는 동시처리의 가능성을 더욱 증대시키기 위해 비동기 파일 읽기로 교체 될수도 있을 것이다. 만약 파일 읽기가 비동기로 수행이 된다면, HTTP 핸들러에 의한 동기적 작업은 오직 HTTP 프로토콜 요청 분석만이 남게 된다.
Proactive 모델의 단점은 프로그래밍 로직이 최소한 Reactive 모델만큼 복잡하다는 것이다.
더군다나, Proactor 패턴은 디버깅이 어려울수 있는데, 비동기 동작들은 때때로 예측불가능하고 반복적이지 않는 실행 순서를 가지기 때문에 분석 및 디버깅을 복잡하게 하기 때문이다.
7 장에서는 다른 패턴들, 예를 들면, 비동기 완료 토큰(Asynchronous Completion Token [8])을 비동기 어플리케이션 프로그래밍 모델을 단순화 시키기 위해 어떻게 적용하는지 기술하고 있다.
3. 적용 가능한곳
다음 조건들을 하나 이상 가지고 있는 경우에 Proactor 패턴을 사용한다.
- 하나 혹은 그이상의 비동기 동작들을 호출 쓰레드의 블럭킹없이 수행하는것이 필요한 경우.
- 비동기 동작들의 완료를 통지 받아야만 하는 경우.
- 동시처리 전략을 입/출력 모델에 독립적으로 변경할 필요가 있는 경우.
- 어플리케이션 독립적인 기반 구조로 부터 어플리케이션에 의존적인 로직을 분리함으로서 이득을 보는경우.
- 멀티쓰레드 접근방식이나 반응 디스패칭 접근방식으로는 성능 요구 사항들을 만족시킬수 없는 경우.
4. 구조 및 구성 요소들
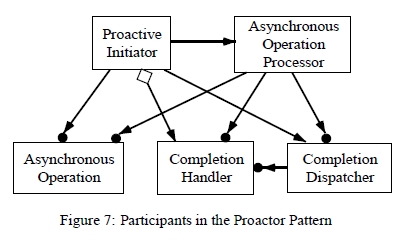
Proactor 패턴의 구조는 OMT(역자주: object modeling Technique, 이 논문이 나온 시점은 UML이 널리 사용되기 전이다. ) 표기를 이용해서 그림7에 설명되었다.
Proactor 패턴의 핵심 참여자(구성요소)들은 다음과 같다 :
-
Proactive 개시자(Initiator) (웹서버 어플리케이션의 메인 쓰레드): * Proactive 개시자는 비동기 작업을 일으키는 어플리케이션내의 모든 존재를 의미한다. 완료 핸들러와 완료 디스패처를 비동기 작업 프로세서(완료시 통지를 보내줄)에 등록한다.
-
완료 핸들러 (Acceptor 와 HTTP 핸들러): * Proactor 패턴은 비동기 작업의 완료를 통지하기 위해, 어플리케이션에 의해 구현된 완료 핸들러 인터페이스들을 사용한다.
-
비동기 작업 (비동기 읽기, 비동기 쓰기 그리고 비동기 Accept): 비동기 작업들은 어플리케이션들 대신에 요청들(압/출력 및 타이머 작업들)을 실행하기 위해 사용된다. 어플리케이션이 비동기 작업들을 시작할때, 그 작업들은 어플리케이션의 쓰레드를 빌리지 않고 수행된다. 그러므로 어플리케이션의 관점에서 보면 작업들은 비동기적으로 수행 된다. 비동기 작업들이 완료되면, 완료 디스패처가 어플리케이션으로 통지를 보낸다 (이는 비동기 작업 프로세서가 어플리케이션에게 통지하는 역활을 완료 디스패처에게 위임했기 때문이다).
-
비동기 작업 프로세서 Asynchronous Operation Processor (운영 시스템): 비동기 작업들은 비동기 작업 프로세서에 의해서 완료될때까지 동작된다. 이 구성요소는 일반적으로 운영체계에 의해 구현된다.
-
완료 디스패처 (Notification Queue): 비동기 작업이 완료되았을때 어플리케이션의 완료 핸들러를 콜백하는 역활이다. 비동기 작업 프로세서가 비동기로 시작된 작업을 완료했을때, 완료 디스패처가 어플리케이션의 콜백을 대신 수행한다.
5. 협업(Collaborations)
모든 비동기 작업들에게서 일어나는 몇가지 잘 정의된 단계들이 있다.
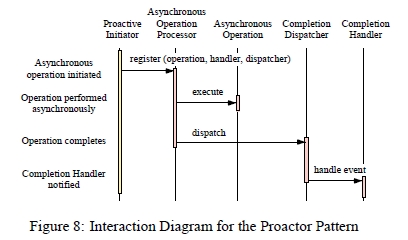
고수준의 추상 개념에서, 어플리케이션은 작업을 비동기로 시작시키고, 작업들의 완료시점에 통지를 받는다. 그림 8 은 패턴 참여자들 사이에서 발생되어야 하는 다음과 같은 상호 작용들을 보여분다.
-
Proactive 시작자들이 작업을 시작시킨다 : 비동기 작업을 수행하기 위해, 어플리케이션은 비동기 작업 프로세서에 작업을 시작시킨다. 예를 들어, 웹서버는 특정 소켓 연결을 이용해서 네트워크를 통한 파일 전송을 OS에게 요청할수 있다. 이런 작업을 요청하기 위해서, 웹서버는 사용할 파일과 네트워크 연결을 지정해야만 한다. 또한 웹서버는
- 작업이 완료될때 어떤 핸들러가 통지를 받을 것인지 그리고
- 파일이 전송되었을때 어떤 완료 디스패처가 콜백을 수행할것인지를 지정해야 한다.
-
비동기 작업 프로세서가 작업을 수행한다 : 어플리케이션이 비동기 작업 프로세서에 대해 작업들의 실행을 요청시, 다른 어플리케이션의 작업들에 대해서 비동기적으로, 그것들을 실행한다. 최근의 운영체계(솔라리스나 Windows NT같은)들은 비동기 입/출력 서브시스템들을 커널내에서 지원한다.
-
비동기 작업 프로세서가 완료 디스패처에게 통지를 보냄 : 작업들이 완료됬을때, 비동기 작업 프로세서는 작업 시작시 지정됬던 완료 핸들러와 완료 디스패처를 검색한다. 그리고 비동기 작업 프로세서는 완료 디스패처에게 비동기 작업의 결과와 콜백할 완료 핸들러를 전달한다. 예를 들면, 파일이 비동기로 전송되었다면, 비동기 작업 프로세서는 완료 상태(즉 성공이나 실패같은) 와 더불어 네트워크 연결에 전송된 바이트수를 보고할수 있다.
-
완료 디스패처가 어플리케이션에 알림 : 완료 디스패처가 완료 핸들러를 호출하면서, 어플리케이션에서 지정한 완료 데이터를 전달한다. 예를 들어, 비동기 읽기 동작이 완료하는 경우라면, 완료 핸들러는 새로 도착한 데이터에 대한 포인터를 전달받게 될것이다.
6. 결론
이장에서는 Proactor 패턴 사용에 대한 결론들을 상세하게 알아본다
6.1 이점들
Proactor 패턴은 다음의 이점들을 제공한다
-
처리해야하는 작업들을 더 많이 분리시킬 수 있다 : Proactor 패턴은 어플리케이션에 독립적인 비동시성 절차들을 어플리케이션 고유의 기능들로부터 분리시킨다. 어플리케이션에 독립적인 절차들은 재사용 가능한 요소들이 되며, 이것들은 비동기 작업에 연관되어진 완료이벤트들을 어떻게 디멀티플렉스 할것인지, 완료 핸들러에 의해 정의된 적절한 콜백 메서드를 어떻게 호출할것인지를 알고있다. 마찬가지로, 어플리케이션 고유의 기능은 특정 형태의 서비스 (예를 들면 HTTP 처리같은)를 어떻게 수행할지 알고 있다.
-
향상된 어플리케이션 로직 이식성 : 이벤트 디멀티플렉싱을 수행하는 OS에 대해 독립적으로 재사용되는 인터페이스 호출을 허용하므로, 어플리케이션의 이식성을 향상시킨다. 이 시스템 호출들은 여러개의 이벤트 발생자들에게서 동시에 발생될수 있는 이벤트들을 감지하고 보고한다. 이벤트 발생자들은 입/출력 포트들, 타이머들, 동기화 객체, 시그널들, 등등이 될수 있다. 실시간 POSIX 플랫폼에서ㅡ 비동기 입/출력 함수들이 aio 계열 함수들[9] 에 의해서 제공된다. Windows NT에서는 I/O 완료포트(completion ports) 와 중첩(overlapped) I/O가 비동기 I/O [10]를 구현하기 위해 사용된다.
-
완료 디스패처 는 동시처리 방법을 캡슐화 시킨다 : 비동기 작업 프로세서로부터 완료 디스패처를 분리하는것의 장점은, 다른 패턴 참여자들에게 영향을 주지 않고 다양한 동시처리 전략을 완료 디스패처에 설정할수 있다는 점이다. 7장에서 논의된것처럼, 완료 디스패처는 몇몇 동시처리 전략들(단일 쓰레드와 쓰레드 풀 방안)을 이용하기 위해 설정 가능하다.
-
쓰레드 정책이 동시처리 정책에서 분리된다 : 비동기 작업 프로세서는 Proactive 시작자를 대신해서 장시간이 쇼요될수 있는 작업을 완료하기 때문에, 어플리케이션은 동시처리를 증대시키기 위해 쓰레드들을 생성하지 않아도 된다. 이것은 동시처리 정책을 쓰레드 정책에 독립적으로 변경시킬수 있게 한다. 예를 들면, 동시에 많은 클라이언트에게 서비스를 하는것을 원하지만, CPU 당 하나의 쓰레드만을 가지기를 원하는 웹서버가 있을 수 있다.
-
성능 향상 : 멀티 쓰레드 기반 운영시스템은 제어되는 다수의 쓰레드를 순회하기 위해 문맥전환을 수행한다. 문맥전환을 수행하기 위한 시간은 꽤 일정한 편이지만, 만약 운영체계가 놀고있는 쓰레드로 문맥을 전환시킨다면 많은수의 쓰레드 사이를 순회하는데 소요되는 전체 시간은 어플리케이션의 성능을 심각하게 떨어뜨릴수 있다. 예를 들어, 완료상태를 알아내기 위해 비효율적인 폴링(polling)을 수행하는 쓰레드를 사용 할 수도 있지만, Proactor 패턴을 이용하면 처리할 이벤트가 있는 논리적 쓰레드들만을 활성화 시킴으로서 문맥 전환 비용을 막을수 있다. 웹서버의 예를 들면, 처리되어야할 GET요청이 없다면 HTTP핸들러를 활성화 시킬 필요가 없다.
-
단순해지는 어플리케이션 동기화 : 완료 핸들러가 추가적인 쓰레드들을 생성하지 않는 한, 동기화 문제들에 대해 거의 고려할 필요없이 어플리케이션 로직을 작성 할수 있다. 완료 핸들러들은 전통적인 단일 쓰레드 환경에서 존재하는것처럼 작성되어 질수 있다. 웹서버를 예를 들면, HTTP GET 핸들러는 비동기 읽기 동작(Windows NT TransmitFile 함수 [1]같은)을 통해서 디스크에 접근 가능하다.
6.2 단점들
Proactor 패턴은 다음과 같은 단점들을 가지고 있다 :
-
디버그가 어렵다: 뒤집힌(inverted) 제어의 흐름이 프레임워크의 기반구조와 어플리케이션 고유 핸들러에 있는 메서드 콜백사이를 왔다 갔다 하기 때문이다. 이것은 디버거내에서 런타임시의 단일 stepping (역자주: 디버깅시 next 기능) 의 어려움을 증대시키는데, 어플리케이션 개발자는 프레임워크(즉 OS)의 코드를 이해할수 없거나 코드에 접근할수 없을수 있기 때문이다. 이것은 LEX 과 YACC로 작성된 컴파일러의 lexical 분석기와 파서에 디버그를 시도할때 마주하게 되는 문제들과도 비슷하다. 이 어플리케이션들에서는, 제어 쓰레드가 사용자 정의 액션 루틴에 있는 경우의 디버깅은 명확하다. 하지만 생성된 결정적 유한 오토마타 - Deterministic Finite Automata (DFA) - skeleton으로 제어 쓰레드가 돌아오게 되면, 프로그램 로직을 따라가기가 힘들다.
-
미 처리된 작업들의 스케쥴링과 제어 : Proactive 시작자는 비동기로 작업 실행에 있어서 순서에 대한 제어권을 갖지 않을수 있다. 그러므로, 비동기 작업 프로세서는 비동기 작업들에 대한 우선 순위 매김과 취소를 지원하게끔 조심스럽게 설계되어야 한다.
7. 구현
Proactor 패턴은 다양한 방법으로 구현될수 있다.
이장에서는 Proactor 패턴을 구현하느데 필요한 단계들을 기술한다.
7.1 비동기 작업 프로세서의 구현
첫번째 단계는 어플리케이션을 대신해서 비동기 작업을 수행하는 비동기 작업 프로세서를 만드는 것이다. 따라서 이것의 주요한 2가지 책임은 비동기 동작 API들을 제공하는것과 그 일을 하기위한 비동기 동작 엔진을 구현하는것이 된다.
7.1.1 비동기 동작 API들을 정의
비동기 작업 프로세서는 어플리케이션이 비동기로 작업을 수행할수 있게끔 API를 제공해야 한다. 이러한 API들을 설계하는데는 몇가지 고려사항들이 존재한다 :
-
이식성: API들은 어플리케이션이나 Proactve 시작자들을 특정 플랫폼에 구속시키면 안된다.
-
적응성: 때때로, 비동기 API들은 많은 종류의 작업들에게 공유될 수 있다. 예를들면, 여러 수단(네트워크나 파일들)들에서 입/출력을 수행 하기위해 비동기 I/O 동작들이 자주 사용되어질수 있다. 그러한 재사용을 지원하는 API들을 설계하는것이 이득일 것이다.
-
콜백들: Proactve 시작자들은 비동기 동작이 호출될때, 콜백을 등록해야 한다. 콜백을 구현하는 일반적인 접근방식은 호출객체들(클라이언트들)에게 호출자(서버)가 알고있는 인터페이스를 제공하게 하는 것이다. 그러므로,Proactive 시작자들은 비동기 작업 프로세서에게 어떤 완료핸들러가 작업완료시에 콜백 되어져야 하는지 알려줘야만 한다.
-
완료 Dispatcher: 어플리케이션은 여러개의 완료 Dispatcher들을 사용할수 있기 때문에, Proactive 시작자는 어떤 완료 디스패처가 콜백을 수행해야 하는지도 지시해야 한다.
이러한 사항들을 모두 고려한, 다음 비동기 읽기, 쓰기 API를 생각해보자.
Asynch_Stream 클래스는비동기 읽기, 쓰기들을 시작하기 위한 일종의 팩토리이다. 일단 생성되면, 이 클래스를 이용해서 다수의 비동기 읽기, 쓰기 작업들이 시작될수 있다.
Asynch Stream::Read 의 결과는 비동기 읽기가 완료될때 완료핸들러의 handle_read 콜백을 통해서
핸들러에게 전달된다. 비슷하게, Asynch_Stream::Write 의 결과는 비동기 쓰기가 완료될때
완료핸들러의 handle_write 콜백을 통해서 핸들러에게 전달된다.
class Asynch_Stream
// 비동기 읽기와 쓰기를 시작하기 위한 팩토리 클래스.
{
// 팩토리를 각 비동기 호출에서 사용될 정보를 가지고 초기화 한다.
// <handler> 는 작업 완료시에 통지를 받는다.
// 비동기 동작들은 <handler>상에서 수행되고, 그결과들은 <Completion_Dispatcher>로 보내진다.
Asynch_Stream (Completion_Handler &handler,HANDLE handle,Completion_Dispatcher \*);
// 비동기 읽기를 시작한다. <bytes_to_read>크기만큼 읽어지고 <message_block>안에 저장된다.
int read (Message_Block &message_block, u_long bytes_to_read, const void *act = 0);
// 비동기 쓰기를 시작한다. <message_block>으로부터 <bytes_to_write>크기만큼 가져와서 써진다.
int write (Message_Block &message_block,u_long bytes_to_write,const void *act = 0);
...
};
7.1.2 비동기 작업 엔진의 구현
비동기 작업 프로세서는 작업을 비동기로 수행하는 방법을 포함해야 한다. 즉, 어플리케이션 쓰레드가 비동기적 작업을 실행시켰을때, 그 작업은 어플리케이션의 쓰레드 제어를 빌리지 않고 수행이 되어야만 한다. 다행히, 현대의 운영체계들은 비동기 작업을 위한 방법들(예를 들면, POSIX 비동기 입/출력과 WinNT의 중첩 입/출력)을 제공하고 있다.
이런 경우에는 이 부분을 구현하는것은 간단하다. 플랫폼 API들을 위에 설명된 비동기 작업 API들과 맵핑만 시켜주면 된다.
만약 운영체계가 비동기 작업들을 지원하지 못하는 경우 비동기 작업 엔진을 만들기 위해 가능한 몇가지 기법이 존재하는데, 아마도 제일 직관적인 해결책은 어플리케이션들을 위한 작업들을 비동기로 수행하기 위한 전담 쓰레드들을 사용하는 것이다.
쓰레드로 처리되는 비동기 작업 엔진을 구현하기 위해서는 3가지 주요한 절차들이 존재한다 :
-
작업 호출 : 작업은 어플리케이션 쓰레드를 호출하는 것으로부터 시작되어, 서로 다른 쓰레드에서 수행되기 때문에 어떤 형태로던지 쓰레드 동기화가 발생된다. 각 동작마다 쓰레드 하나씩을 생성하는 것이 하나의 접근법일수도 있다. 가장 일반적인 접근법은 비동기 작업 프로세서를 위한 전담 쓰레드들의 풀(pool)을 제어하는 것이다. 이것은 어플리케이션 쓰레드가 다른 어플리케이션의 연산들을 계속하기 전에 먼저 작업요청을 큐에 저장하는것을 필요로 할것이다.
-
작업 실행 : 작업이 전담 스레드에서 수행되므로, 어플리케이션 진행에 방해없이 블럭킹 동작들이 수행될수 있다. 예를 들어, 비동기 입/출력 “읽기”를 위한 방법을 제공할때, 전담 쓰레드는 소켓이나 파일핸들로 부터 읽어오는 동안 블럭되어도 된다.
-
작업 완료 : 작업 완료시, 어플리케이션이 통지를 받아야 한다. 특히, 그 전담 스레드는 어플리케이션 특정적인 통지들을 완료 디스패처에게 위임시켜야 한다. 이것은 스레들간 추가적인 동기작업을 필요로 할것이다.
– 번역중